
CareSpoon: 한식 분류기 만들기 A to Z
YOLOv5 custom dataset으로 학습시키기
현재 졸업 프로젝트에서 음식 이미지에서 음식을 인식해서 섭취한 영양 성분을 분석하고 영양 상태를 관리해주는 <CareSpoon: 식단 이미지 분석을 통한 시니어 식습관 모니터링 서비스>를 개발하고 있다.
나는 음식 이미지에서 음식 메뉴를 추론하는 AI 모델링과 AI 모델 서버 파트를 맡았다. 아래 사진과 같이 우리 팀 노션 페이지에서 모든 태스크 및 일정을 관리하면서 개발중이다. 지금은 FastAPI로 AI 모델 api까지 개발 완료했고, EC2로 배포중이다.


직접 데이터를 구축하고, GPU를 사용하기 위해 개발환경을 세팅하고, 리눅스 환경에서 모델을 학습시킨 것이 처음이라 CUDA, cuDNN 등 개발환경 셋업부터 쉽지 않았다.
그래서 프로젝트 과정을 최대한 자세하게, 처음부터 끝까지 기록하려고 한다. 이번 포스팅에서는 AI HUB에서 구한 custom datset으로 YOLOv5를 학습시키는 모든 과정을 담아볼 것이다.
다시 한번 프로젝트에서 내 Goal을 한 문장으로 정리하면 다음과 같다.
🚩 여러 음식이 있는 식단 이미지에서 음식을 분류하는 Object Detection 모델을 만들고, API 개발하기
0. 개발 환경 셋업
개발 환경 및 사용한 기술 스택은 다음과 같다. Putty의 SSH로 Tencent Cloud의 Ubuntu Server 환경에서 모델을 학습시켰다.
클라우드: Tencent Cloud
- OS: Ubuntu Server 20.04 LTS 64bit
- CPU: 8-core
- MEM: 32GB
- GPU: 1 NVIDIA T4
모델: YOLOv5
1. YOLOv5 학습 환경 세팅하기 | Anaconda 가상환경 만들기
필자의 PC 환경은 다음과 같다.
- OS: Ubuntu 20.04 (& Window 10)
- CUDA : 11.3
- cuDNN : 8.2.1
- Anaconda 환경
Anaconda 다운로드
튜토리얼(Anaconda 설치 (on Ubuntu 20.04 LTS)) 대로 콘다 가상환경 셋업을 위해 아나콘다를 설치한다.
# download
wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh
# start install process
sudo bash Anaconda3-2021.05-Linux-x86_64.sh
Anaconda3 will now be installed into this location:
/root/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/root/anaconda3] >>>
Anaconda 설정하기
source /usr/anaconda3/bin/activate
conda init
source ~/.bashrc
conda config --set auto_activate_base True

위와 같이 conda --version 명령어가 제대로 실행되면, 아나콘다 설치가 끝났고 이제 개발환경을 만들면 된다.
가상환경 생성
#가상환경 생성
conda create -n yolov5 python=3.8
#가상환경 실행
conda activate yolov5
PyTorch 설치
# CUDA 11.3
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c pytorch -c conda-forge
PyTorch cuda 사용 가능 여부 확인
conda activate yolov5
python
>>import torch
>>torch.cuda.is_available()
Yolov5 git clone하기
내 컴퓨터(GPU)에 맞는 dependency를 맞추기 위해 yolov5에서 권장하는 requirement.txt 파일을 설치하지 않았다. 이제 개발에 필요한 모든 준비가 끝났다!
2. 학습 데이터셋 선정 및 다운로드
- 데이터셋: AI HUB 음식 이미지 및 영양정보 텍스트
내가 구한 데이터셋은 약 2TB로 데이터셋이 너무 많아서 일단 음식 3종류만 선정해서 테스트해보기로 했다. 이 포스팅에서는 쌀밥, 배추김치, 미역국을 학습시키고 테스트할 것이다. 데이터셋을 YOLOv5 형식에 맞춰야 하는데, 먼저 가지고 있는 데이터셋을 살펴보는 게 필요하다.
YOLOv5 라벨은 0번부터 설정해야 하므로 라벨이 저장되어 있는 txt 파일의 내용을 모두 수정해줘야 한다. 그리고 내가 구한 데이터셋은 모든 음식의 라벨이 다 1로 되어 있어서 라벨 값도 올바르게 수정이 필요했다. 그릇, 흰쌀밥, 미역국, 배추김치 데이터셋의 라벨을 각각 0, 1, 2, 3로 수정했다.
그릇 - 0
흰쌀밥 - 01011001 - 1
미역국 - 04011005 - 2
배추김치 - 12011008 - 3
3. 데이터 전처리
다음 파이썬 코드를 이용해서 라벨 값을 올바르게 수정해줬다.
import os
# 폴더 경로 설정
folder_path = 'labels/04011005'
# 폴더 안에 있는 모든 txt 파일 경로 가져오기
file_paths = [os.path.join(folder_path, f) for f in os.listdir(folder_path) if f.endswith('.txt')]
# 각각의 txt 파일을 열어서 수정할 내용을 변경하고, 파일을 다시 씁니다.
for file_path in file_paths:
# 파일 열기
with open(file_path, 'r') as f:
# 파일 내용 읽어오기
content = f.readlines()
# 수정할 내용 변경하기
content_list = list(content[1])
content_list[0] = 4
content = content[0] + ''.join(map(str, content_list))
content = ''.join(content)
# new_content = [line.replace('old_text', 'new_text') for line in content]
# 변경된 내용으로 파일 쓰기
with open(file_path, 'w') as f:
f.writelines(content)
학습 데이터셋의 라벨이 모두 올바르게 수정되었다. yolov5/data/coco.yaml 파일도 다음과 같이 수정해야 한다.
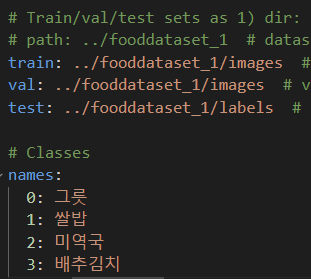
4. 데이터 옮기기
데이터셋을 윈도우 PC에서 다운받고, 모델 학습은 텐센트 클라우드의 우분투 서버에서 하므로 윈도우에서 우분투 서버로 데이터를 옮겨줘야 한다. 나는 Winscp라는 프로그램을 다운 받아서 파일들을 옮겨줬다. (Winscp 다운로드 및 설치) 리눅스 서버의 터미널에서 scp 명령어를 이용하는 방법이 훨씬 빠르긴 하다.
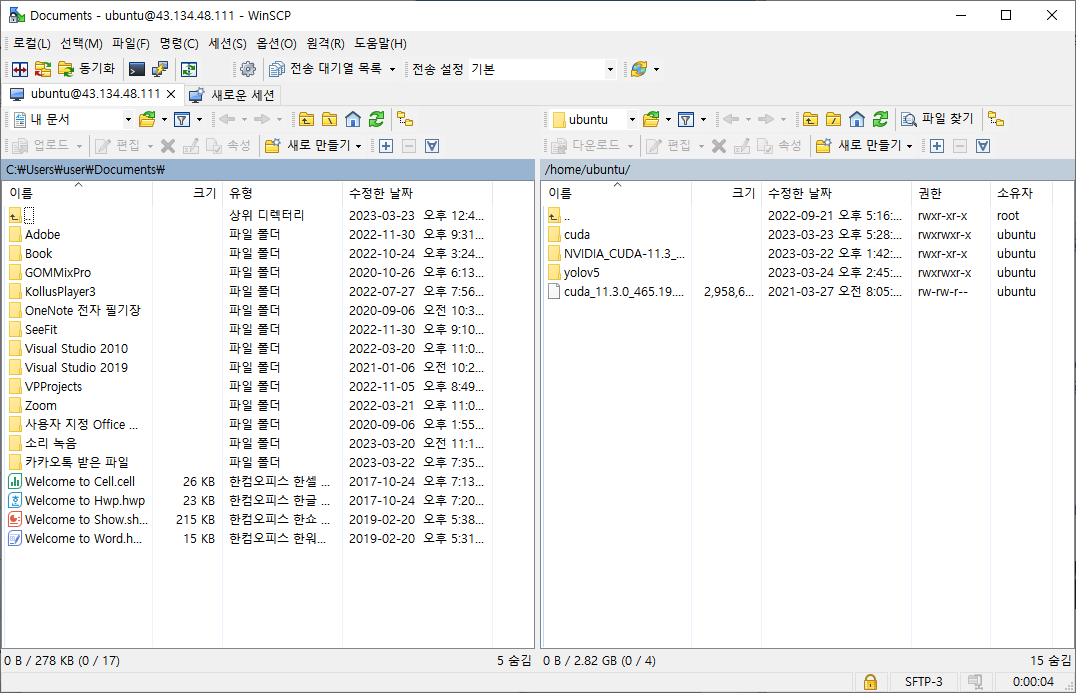
5. 모델 학습시키기
$ conda activate yolov5
$ python train.py --img 416 --batch 16 --epochs 100 --data coco.yaml --weights yolov5s.pt


6. 테스트하기
python detect.py --source=/home/ubuntu/yolov5/fooddataset_1/test/fooddataset_1_002.jpg --weights=/home/ubuntu/yolov5/runs/train/exp4/weights/best.pt --img 416 --conf 0.5


위와 같이 테스트 결과가 잘 나왔다!
YOLOv5는 프레임워크화가 정말 잘 되어 있어서 사용하기 편하다. 하지만 처음 해보는 사람 입장에서는 커스텀 데이터셋도 프레임워크의 인풋 형식에 맞춰야 하고 개발환경 셋업도 해야 하고, 뚝딱 해내기는 쉽지 않았다. 그래도 레퍼런스가 정말 많고, 공식 문서도 정리가 잘 되어 있으니 처음 하는 사람도 할 만한 것 같다. 꼭 공식 문서를 잘 확인하시길!!